|
Top 10 Big Data platforms
April 25, 2024 | Editor: Michael Stromann
26
Big Data platforms allow to manage and analyse data sets so large and complex that it becomes difficult to process using on-hand data management tools or traditional data processing applications. They use a network to solve problems involving massive amounts of data and computation. Big Data platforms can be deployed in local data center or used from the Cloud (Big Data as a Service).
1
Snowflake is the only data platform built for the cloud for all your data & all your users. Learn more about our purpose-built SQL cloud data warehouse.
2
The most sophisticated, open search platform. Transform your data into actionable observability. Protect, investigate, and respond to complex threats by unifying the capabilities of SIEM, endpoint security, and cloud security.
3
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
4
Apache Spark is a fast and general engine for large-scale data processing. Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. Write applications quickly in Java, Scala or Python. Combine SQL, streaming, and complex analytics.
5
The Apache Hive data warehouse software facilitates querying and managing large datasets residing in distributed storage. Hive provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL. At the same time this language also allows traditional map/reduce programmers to plug in their custom mappers and reducers when it is inconvenient or inefficient to express this logic in HiveQL.
6
Cloudera helps you become information-driven by leveraging the best of the open source community with the enterprise capabilities you need to succeed with Apache Hadoop in your organization. Designed specifically for mission-critical environments, Cloudera Enterprise includes CDH, the world’s most popular open source Hadoop-based platform, as well as advanced system management and data management tools plus dedicated support and community advocacy from our world-class team of Hadoop developers and experts. Cloudera is your partner on the path to big data.
7
Apache Cassandra is an open source distributed database management system designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure. Cassandra offers robust support for clusters spanning multiple datacenters, with asynchronous masterless replication allowing low latency operations for all clients.
8
Amazon Redshift is a fast, fully managed, petabyte-scale data warehouse service that makes it simple and cost-effective to efficiently analyze all your data using your existing business intelligence tools. You can start small for just $0.25 per hour with no commitments or upfront costs and scale to a petabyte or more for $1,000 per terabyte per year, less than a tenth of most other data warehousing solutions.
9
Teradata Aster features Teradata Aster SQL-GR analytic engine which is a native graph processing engine for Graph Analysis across big data sets. Using this next generation analytic engine, organizations can easily solve complex business problems such as social network/influencer analysis, fraud detection, supply chain management, network analysis and threat detection, and money laundering.
10
Unified Data Analytics Platform - One cloud platform for massive scale data engineering and collaborative data science.
11
Amazon EMR is a service that uses Apache Spark and Hadoop, open-source frameworks, to quickly & cost-effectively process and analyze vast amounts of data.
12
Presto is a highly parallel and distributed query engine for big data, that is built from the ground up for efficient, low latency analytics.
13
BigQuery is a serverless, highly-scalable, and cost-effective cloud data warehouse with an in-memory BI Engine and AI Platform built in.
14
Apache Impala is a modern, open source, distributed SQL query engine for Apache Hadoop.
15
HDInsight is a Hadoop distribution powered by the cloud. This means HDInsight was architected to handle any amount of data, scaling from terabytes to petabytes on demand. You can spin up any number of nodes at anytime. We charge only for the compute and storage you actually use.
16
Vertica offers organizations new and faster ways to store, explore and serve more data. Vertica lets organizations store data in a cost-effectively, explore it quickly and leverage well-known SQL-based tools to get customer insights. By offering blazingly-fast speed, accuracy and security, it offers operational advantages to the entire organization.
17
Schema-free SQL Query Engine for Hadoop, NoSQL and Cloud Storage. Get faster insights without the overhead (data loading, schema creation and maintenance, transformations, etc.). Analyze the multi-structured and nested data in non-relational datastores directly without transforming or restricting the data
18
Qubole is a Big Data as a Service (BDaas) Platform Running on Leading Cloud Offerings Like AWS. Qubole enables you to utilize a variety of Cloud Databases and Sources, including S3, MySQL, Postgres, Oracle, RedShift, MongoDB, Vertica, Omniture, Google Analytics, and your on-premise data
19
The MapR Distribution for Apache Hadoop provides organizations with an enterprise-grade distributed data platform to reliably store and process big data. MapR packages a broad set of Apache open source ecosystem projects enabling batch, interactive, or real-time applications. The data platform and the projects are all tied together through an advanced management console to monitor and manage the entire system.
20
Build, deploy, and run data processing pipelines that scale to solve your key business challenges. Google Cloud Dataflow enables reliable execution for large scale data processing scenarios such as ETL, analytics, real-time computation, and process orchestration.
21
Google Cloud Dataproc is a managed Hadoop MapReduce, Spark, Pig, and Hive service designed to easily and cost effectively process big datasets. You can quickly create managed clusters of any size and turn them off when you are finished, so you only pay for what you need. Cloud Dataproc is integrated across several Google Cloud Platform products, so you have access to a simple, powerful, and complete data processing platform.
22
SAP HANA converges database and application platform capabilities in-memory to transform transactions, analytics, text analysis, predictive and spatial processing so businesses can operate in real-time.
23
IBM Netezza appliances - expert integrated systems with built in expertise, integration by design and a simplified user experience. With simple deployment, out-of-the-box optimization, no tuning and minimal on-going maintenance, the IBM PureData System for Analytics has the industry’s fastest time-to-value and lowest total-cost-of-ownership.
24
1010data provides a cloud-based platform for big data discovery and data sharing that delivers actionable, data-driven insights quickly and easily. 1010data offers a complete suite of products for big data discovery and data sharing for both business and technical users. Companies look to 1010data to help them become data-driven enterprises.
Latest news about Big Data platforms
2022. Cloudera launches its all-in-one SaaS data lakehouse
Cloudera, the company that specializes in big data with a focus on Hadoop, is now shifting its focus towards becoming the unified data fabric for hybrid data platforms. Taking a step further in this direction, the company recently launched its Cloudera Data Platform (CDP) One, a data lakehouse as a service (LaaS). This managed offering aims to provide enterprises with a platform that enables self-service analytics and data access for a broader range of employees. While Databricks, known for popularizing the lakehouse concept, also offers SaaS-based solutions, Cloudera positions its service as the "first all-in-one data lakehouse SaaS offering." Cloudera emphasizes that its service combines compute, storage, machine learning, streaming analytics, and enterprise security, making it a comprehensive solution for organizations.
2021. Firebolt raises $127M for its new approach to cheaper and more efficient big data analytics
Snowflake revolutionized the realm of data warehousing for numerous companies, opening up new possibilities. Now, a startup aiming to disrupt the disruptor, Firebolt, has successfully secured $127 million in Series B funding. Firebolt asserts that its performance surpasses other data warehouses by up to 182 times, thanks to its SQL-based system. This system incorporates groundbreaking techniques in compression and data parsing, derived from academic research that had not yet been implemented elsewhere. By employing these innovative methods, Firebolt enables data to be handled more efficiently, resulting in lighter data footprints. Consequently, data lakes can seamlessly integrate with a broader data ecosystem, significantly reducing the cloud capacity requirements and lowering costs for organizations.
2020. Panoply raises $10M for its cloud data platform
Panoply, a platform dedicated to simplifying the setup of data warehousing and enabling data analysis through standard SQL queries, has successfully raised $10 million in funding. Since its launch in 2015, the company has remained committed to its original vision of democratizing access to data warehousing and the accompanying analytics capabilities. In recent years, Panoply has expanded its platform by incorporating more code-free data integrations, allowing businesses to effortlessly import data from a diverse range of sources. Notable integrations include Salesforce, HubSpot, NetSuite, Xero, Quickbooks, Freshworks, and others. Furthermore, Panoply seamlessly integrates with leading data warehousing services such as Google's BigQuery and Amazon's Redshift, along with a comprehensive range of BI and analytics tools.
2020. Altinity grabs $4M to build cloud version of ClickHouse open-source data warehouse
Altinity, the commercial entity responsible for the open-source ClickHouse data warehouse, has recently revealed a $4 million seed round, alongside the introduction of their new cloud service, Altinity.Cloud. Altinity.Cloud provides seamless access to fully operational ClickHouse clusters, accompanied by comprehensive enterprise support throughout the entire application life cycle. The service extends its assistance beyond application design and implementation to include production guidance, effectively merging consulting expertise with cloud infrastructure.
2020. InfoSum raises $15.1M for its privacy-first, federated approach to big data analytics
InfoSum, a London-based startup, has secured $15.1 million in funding for its innovative data-sharing solution. InfoSum has developed a unique approach that enables organizations to share data without actually passing it on to one another. This is achieved through a federated, decentralized architecture that utilizes mathematical representations to organize, interpret, and query the data. While initially targeting the marketing technology sector, InfoSum's solution has broad applications across multiple industries. The decision to focus on martech stemmed from the founder's previous experience at DataSift, although the company plans to expand into other verticals in the future.
2020. Collibra nabs $112.5M for its big data management platform
Collibra, a company specializing in data management, warehousing, storage, and analysis, has secured $112.5 million in Series F funding, valuing the company at $2.3 billion. Originally stemming from Vrije Universiteit in Brussels, Belgium, Collibra now serves approximately 450 enterprises and other prominent organizations. Its clientele boasts renowned names such as Adobe, Verizon, AXA insurance, and various healthcare providers. Collibra's comprehensive product lineup encompasses a wide array of services centered around managing corporate data. These offerings include tools that facilitate compliance with local data protection regulations, ensuring secure data storage, and providing analytics capabilities through various tools and plug-ins.
2020. BackboneAI scores $4.7M seed to bring order to intercompany data sharing

BackboneAI, an emerging startup, has secured a $4.7 million seed investment to assist companies in managing extensive amounts of data, especially when sourced from various external channels. BackboneAI offers an AI platform specifically designed to automate data flows within and between organizations. Its capabilities encompass a wide range of scenarios, such as maintaining accurate and comprehensive data catalogs, coordinating the seamless movement of construction materials between companies, or managing content rights across the entertainment industry.
2019. Starburst raises $22M to modernize data analytics with Presto

Starburst, the company seeking to commercialize the open-source Presto distributed query engine for big data (originally developed at Facebook), has announced a successful funding round, raising $22 million. The primary objective of Presto is to enable anyone to utilize the standard SQL query language for executing interactive queries on vast amounts of data stored across diverse sources. Starburst intends to monetize Presto by introducing several enterprise-oriented features. These additions will primarily focus on enhancing security, such as role-based access control, and integrating connectors to enterprise systems like Teradata, Snowflake, and DB2. Additionally, Starburst plans to provide a management console that empowers users to configure the cluster for automatic scaling, among other functionalities.
2019. HPE acquires big data platform MapR

Hewlett Packard Enterprises (HPE) has completed the acquisition of MapR Technologies, a leading distributor of a data analytics platform based on Hadoop. This strategic deal encompasses the transfer of MapR's technology, intellectual property, and expertise in domains such as AI, machine learning, and analytics data management. By incorporating MapR's portfolio, HPE aims to reinforce its existing offerings in the field of big data, complementing the BlueData software acquisition it made in November. BlueData's software facilitates a container-based approach for deploying and managing Hadoop, Spark, and other environments across bare metal, cloud, or hybrid platforms. The inclusion of the MapR platform brings additional capabilities for running distributed applications, including storage APIs such as S3 API, along with APIs for HDFS, POSIX, NFS, and Kafka.
2018. Big Data platforms Cloudera and Hortonworks merge

Over time, Hadoop, the once-prominent open-source platform, fostered the growth of numerous companies and an ecosystem of vendors. However, the complexity associated with Hadoop posed a significant challenge. This is where companies like Hortonworks and Cloudera stepped in, offering packaged solutions for IT departments seeking the advantages of a big data processing platform without the need to build Hadoop from scratch. These companies provided various approaches to tackle the complexity, but as cloud-based big data solutions gained prominence, the notion of implementing a Hadoop system from scratch became less compelling, even with the assistance of firms like Cloudera and Hortonworks. Today, both companies have announced their merger in a deal valued at $5.2 billion. The combined entity will serve a customer base of 2,500, generate $720 million in revenue, and possess $500 million in cash reserves, all while remaining debt-free.
2016. HP to sell its software business to Micro Focus

Hewlett-Packard Enterprise (HPE) has reached an agreement to sell its software business to Micro Focus in a substantial $8.8 billion deal. One significant component of HP Enterprise software, Autonomy, constitutes a quarter of the total value and was initially acquired by HP for $11 billion in 2011. The software business being sold also encompasses Mercury Interactive, which HP acquired for $4.5 billion in 2006, Vertica for $320 million, and ArcSight for $1.5 billion in 2010. HPE's Chief Executive, Meg Whitman, intends to shift the company's focus towards other sectors such as networking, storage, and technology services following its separation from computer and printer manufacturer HP Inc. in the previous year.
2015. MapR tries to separate from Hadoop
MapR is among the companies operating on the open-source Hadoop platform, facing competition in this domain. To establish a distinctive position among its well-established competitors, MapR has unveiled a new product called MapR Streams. This innovative offering enables the continuous processing of data, allowing for the creation of custom offers by feeding consumer data to advertisers or the distribution of health data to medical professionals to personalize medication and treatment options. These capabilities operate in near real-time, empowering customers to share data sources with individuals or machines that require access to such information through a subscription-based model. For instance, a maintenance program could subscribe to data streams from a manufacturer's shop floor, acquiring insights on usage, production, bottlenecks, and wear and tear. Alternatively, IT departments could subscribe to data streams containing log information, enabling them to detect anomalies that indicate maintenance issues or security breaches.
2015. Google launched new managed Big Data service Cloud Dataproc
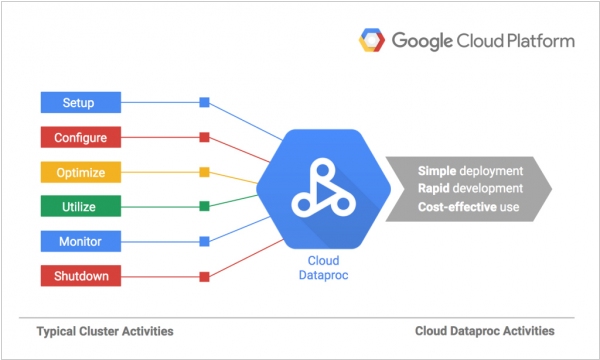
Google is expanding its portfolio of big data services on the Google Cloud Platform with the introduction of Cloud Dataproc. This new service fills the gap between directly managing the Spark data processing engine or Hadoop framework on virtual machines and utilizing a fully managed service like Cloud Dataflow for orchestrating data pipelines on Google's platform. With Cloud Dataproc, users can quickly deploy a Hadoop cluster in less than 90 seconds, which is considerably faster than other available services. Google charges only 1 cent per virtual CPU/hour within the cluster, in addition to the standard costs associated with running virtual machines and storing data. Users can also incorporate Google's more affordable preemptible instances into their clusters to reduce compute costs. Billing is calculated per minute, with a minimum charge of 10 minutes. Thanks to the rapid cluster deployment capabilities of Dataproc, users can easily create ad-hoc clusters when necessary, while Google takes care of the administrative tasks.
2015. Hortonworks acquired dataflow solutions developer Onyara
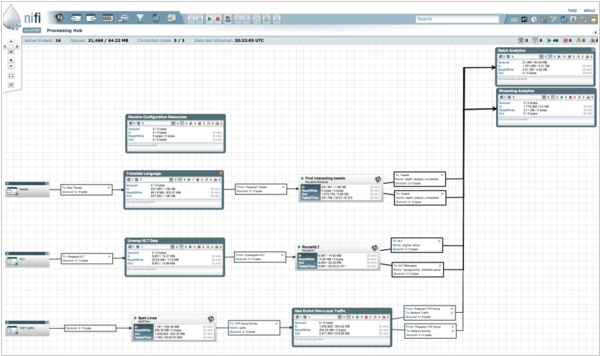
Hortonworks, a publicly traded company that offers a commercial distribution of the open-source big data software Hadoop, has announced its acquisition of Onyara, an early-stage startup known for the development of Apache NiFi. This open-source software originated within the National Security Agency (NSA) and enables efficient delivery of sensor data to appropriate systems while maintaining data tracking capabilities. In addition to previous acquisitions like XA Secure and SequenceIQ, Hortonworks has now expanded its portfolio with the intention of introducing a new subscription service based on Apache NiFi. This subscription will be marketed under the name Hortonworks DataFlow.
2015. Data transformation service Tamr raised $25.2 million
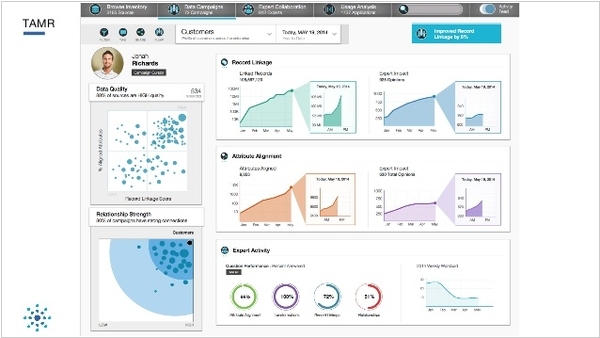
Tamr, a startup focused on helping companies comprehend and consolidate their disparate databases, has announced a successful Series B funding round, securing $25.2 million. Tamr aspires to achieve a transformative impact on the enterprise realm, similar to how Google revolutionized the web. While Google's algorithm scours the internet for web pages, Tamr's algorithm searches for databases. Large companies currently face the challenge of managing numerous databases without a comprehensive understanding of their contained data. This lack of awareness can be perilous, as valuable data may be at risk of unauthorized access or loss without the company's knowledge. Tamr addresses this issue by creating a centralized catalog that encompasses all data sources, including spreadsheets and logs, throughout the organization. By providing greater visibility into a company's data assets, Tamr delivers significant value on multiple fronts, particularly in terms of enhancing security, particularly in the wake of recent high-profile data breaches.
2015. IBM bets on big data Apache Spark project

IBM has made a significant announcement regarding its involvement in the open source big data project Apache Spark. The company plans to allocate a team of 3,500 researchers to this initiative. Additionally, IBM has unveiled its decision to open source its own IBM SystemML machine learning technology. These strategic moves are aimed at positioning IBM as a frontrunner in the domains of big data and machine learning. Cloud, big data, analytics, and security form the pillars of IBM's transformation strategy. In conjunction with this announcement, IBM has committed to integrating Spark into its core analytics products and partnering with Databricks, the commercial entity established to support the open source Spark project. IBM's participation in these endeavors goes beyond mere altruism. By actively engaging with the open source community, IBM aims to establish itself as a trusted contributor in the realm of big data. This, in turn, enhances its credibility among companies working on big data and machine learning projects using open source tools. The collaborative involvement with the community opens doors for IBM to offer consulting services and seize other business opportunities in this space.
2015. MapR adds Apache Drill to its Hadoop distribution

MapR has recently announced that its Hadoop distribution now includes Apache Drill, an open-source SQL query engine designed for Hadoop and NoSQL environments. Apache Drill offers low-latency capabilities, making it easier for end users to interact with diverse data sources, including legacy transactional systems, Internet of Things (IoT) sensors, web click-streams, and semi-structured data. Furthermore, it provides compatibility with popular business intelligence (BI) and data visualization tools. The inclusion of Apache Drill 1.0 in MapR's distribution grants users free access to this powerful tool. As a result, competitors like Hortonworks, who have contributors involved in the Apache Drill project, can also consider incorporating it into their own distribution if they find it valuable.
2015. Google launched NoSQL database Cloud Bigtable

Google is set to introduce a new NoSQL database called Cloud Bigtable, which is built upon its highly reliable Bigtable data storage system. This battle-tested service underpins popular Google applications like Gmail, Google Search, and Google Analytics. Cloud Bigtable is expected to deliver sub-10 millisecond latency and provide 2x better performance per dollar compared to similar offerings such as HBase and Cassandra. It seamlessly integrates with the Hadoop ecosystem through its support for the HBase API and also works with Google's Cloud Dataflow. While Cloud Bigtable is not Google's first NoSQL database in the cloud, the existing Cloud Datastore already offers a high-availability NoSQL datastore for developers on the App Engine platform, which is also based on Bigtable. Cory O'Connor, a Google Cloud Platform product manager, explains that Cloud Datastore is designed for read-heavy workloads in web and mobile applications.
2015. MapR revamps its Hadoop platform with more real-time analytics

The most recent version of the enterprise-grade distributed Hadoop data platform MapR is specifically designed for the modern data-centric enterprise, emphasizing real-time capabilities. Its advanced features include table replication, which enables the simultaneous updating of multiple instances in different locations while ensuring synchronized changes across them. The ability to respond promptly to real-time business needs and offer the right solutions is crucial. Failure to do so not only means missed opportunities but can also pose a threat to a company's sustainability. This is one of the reasons why some enterprises are opting for MapR instead of traditional relational database management systems (RDBMS). MapR provides a comprehensive solution that combines a highly regarded NoSQL database and Hadoop in a convenient package. Unlike competitors such as Hortonworks and Cloudera, MapR stands out as a software company focused on simplifying the implementation of big data solutions, making it more accessible and user-friendly.
2015. Google partners with Cloudera to bring Cloud Dataflow to Apache Spark
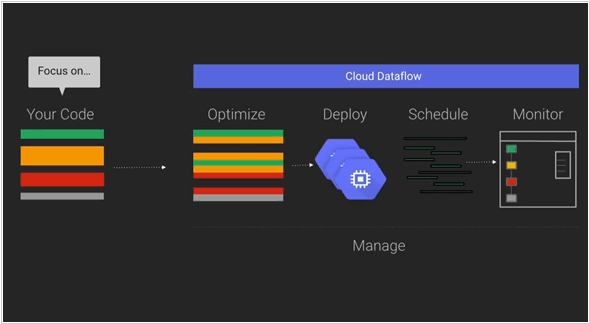
Google has announced a collaboration with Cloudera, the Hadoop specialists, to integrate its Cloud Dataflow programming model into Apache's Spark data processing engine. By bringing Cloud Dataflow to Spark, developers gain the ability to create and monitor data processing pipelines without the need to manage the underlying data processing cluster. This service originated from Google's internal tools for processing large datasets at a massive scale on the internet. However, not all data processing tasks are identical, and sometimes it becomes necessary to run tasks in different environments such as the cloud, on-premises, or on various processing engines. With Cloud Dataflow, data analysts can utilize the same system to create pipelines, regardless of the underlying architecture they choose to deploy them on.
2015. Teradata acquired app marketing platform Appoxee
Analytics company Teradata has recently acquired Appoxee, an Israeli push-messaging startup that focuses on assisting publishers and developers in enhancing user engagement within their applications. The acquisition, valued at approximately $20 million, addresses a significant challenge faced by app developers today: retaining users and encouraging them to actively utilize their apps amidst the constant influx of new applications entering the market. Appoxee provides developers with a solution by leveraging push messages, which serve as reminders to complete a game, deliver updates about app enhancements, or offer coupons for in-app purchases. Additionally, Appoxee offers a platform to facilitate the creation and execution of these push messaging campaigns.
2014. Teradata acquired data-archiving service RainStor

Data warehouse vendor Teradata continues to expand its presence in the realm of Big Data through strategic acquisitions. In its latest move, Teradata has acquired data-archiving specialist RainStor for an undisclosed sum, marking its fourth acquisition this year. RainStor specializes in developing an archival system that can be integrated with Hadoop and claims to achieve data volume compression of up to 95 percent. Teradata's acquisitions, including Hadapt and Think Big Analytics, demonstrate the company's ambition to play a more significant role in organizations' big data environments, transcending its traditional position as a data warehouse and business intelligence provider.
2014. Business analytics provider Palantir raises $50 Million
Palantir, the prominent big data company, has secured an additional $50 million in funding. With a valuation of $9 billion, Palantir already holds a position as one of Silicon Valley's most valuable private technology firms, alongside others that have experienced substantial increases in their worth in recent times. Founded by entrepreneur Peter Thiel in 2004, Palantir initially focused on providing its software, capable of identifying patterns within extensive datasets, to government agencies such as the CIA and NSA. As the year comes to a close, the company anticipates surpassing $1 billion in revenue and is actively seeking to expand its customer base. It has successfully marketed its data analysis technology to Wall Street firms seeking fraud detection capabilities and pharmaceutical companies aiming to streamline drug development processes. Notably, Hershey has leveraged Palantir's tools to uncover connections between weather patterns and consumer behavior.
2014. After IPO, Hortonworks is a $1 billion Hadoop company

Shares of the Hadoop vendor Hortonworks concluded their inaugural trading day at $26.48, resulting in a total market capitalization of $1.1 billion by the end of Friday's trading session. Hortonworks distinguishes itself by exclusively offering open-source software and generating revenue through support and services. The company was established and launched in 2011 when a team of engineers spun it off from Yahoo, which had been at the forefront of driving advancements in the open-source Apache Hadoop project. Despite a challenging trading day for most major stocks, Hortonworks' stock experienced a late rally. Its primary competitors in the pure-play Hadoop sector, Cloudera and MapR, will undoubtedly closely monitor Hortonworks' stock performance in the coming months. MapR, too, boasts a private-market valuation exceeding $1 billion, while Cloudera's valuation surpasses $4 billion.
2014. Big Data as a Service company Qubole raises $13 million

Hadoop-as-a-service startup, Qubole, has secured $13 million in a series B venture capital funding round. Qubole operates on the Amazon Web Services cloud and is also compatible with Google Compute Engine. It functions as a cloud-native Hadoop service, featuring a user-friendly graphical interface, connectors to various data sources (including cloud object stores), and takes advantage of cloud capabilities such as autoscaling and spot pricing for computing resources. Qubole stands out by offering optimized versions of Hive and other MapReduce-based tools, but it also enables data analysis through the use of Facebook's Presto SQL-on-Hadoop engine. Additionally, Qubole is developing a service centered around the Apache Spark framework, which has gained significant popularity due to its speed and efficiency.
2014. MapR partners with Teradata to reach enterprise customers

The last remaining independent Hadoop provider, MapR, and the prominent big data analytics provider, Teradata, have joined forces to collaborate on integrating their respective products and developing a unified go-to-market strategy. As part of this partnership, Teradata gains the ability to resell MapR software, professional services, and provide customer support. Essentially, Teradata will act as the primary interface for enterprises that utilize or aspire to use both technologies, serving as the representative for MapR. Previously, Teradata had established a close partnership with Hortonworks, but it now extends its collaboration and analytic market leadership to all three major Hadoop providers. Similarly, earlier this week, HP unveiled Vertica for SQL on Hadoop, enabling users to access and analyze data stored in any of the three primary Hadoop distributions—Hortonworks, MapR, and Cloudera.
2014. HP plugs the Vertica analytics platform into Hadoop
HP has unveiled the introduction of Vertica for SQL on Hadoop, a significant announcement in the world of analytics. With Vertica, customers gain the ability to access and analyze data stored in any of the three primary Hadoop distributions: Hortonworks, MapR, and Cloudera, as well as any combination thereof. Given the uncertainty surrounding the dominance of a particular Hadoop flavor, many large companies opt to utilize all three. HP stands out as one of the pioneering vendors by asserting that "any flavor of Hadoop will do," a sentiment further reinforced by its $50 million investment in Hortonworks, which currently represents the favored Hadoop flavor within HAVEn, HP's analytics stack. HP's announcement not only emphasizes the platform's interoperability but also highlights its capabilities in dealing with data stored in diverse environments such as data lakes or enterprise data hubs. With HP Vertica, organizations gain a seamless solution for exploring and harnessing the value of data stored in the Hadoop Distributed File System (HDFS). The combination of Vertica's power, speed, and scalability with Hadoop's prowess in handling extensive data sets serves as an enticing proposition, potentially motivating hesitant managers to embrace big data initiatives confidently. HP's comprehensive offering provides a compelling avenue for organizations to unlock the potential of their data, urging them to venture beyond their reservations and embrace the world of big data.
2014. Enterprise Hadoop provider Hortonworks filed for an IPO

Hortonworks, the company developing commercial Hadoop technology, has submitted its initial public offering (IPO) filing. With over $33 million in revenue and an operating loss of nearly $88 million, the company has showcased its financial performance for the current year. Hortonworks emerged as a separate entity from Yahoo in 2011 and provides a comprehensive big data processing platform. This platform enables the processing of diverse data types, including SQL and NoSQL sources, and facilitates data search and visualization using various analytics tools. Hortonworks is renowned for its exclusive focus on Hadoop, offering a solution devoid of any proprietary extensions.
2014. IBM adds Netezza analytics as a service to its cloud
IBM has unveiled a range of new cloud data services for IBM Cloud, expanding its offerings with several innovative tools. These additions include DataWorks, an intelligent data-preparation tool, dashDB, an in-memory analytic database powered by Netezza, and a localized version of the cloud-based database Cloudant. This comprehensive set of capabilities showcases IBM's commitment to enhancing its Bluemix platform. Notably, dashDB positions IBM alongside industry giants like Amazon Web Services, Google, and Microsoft, as it introduces its own analytic service built on columnar database technology, further solidifying its presence in this domain.
2014. The Netezza team is back with Big Data startup Cazena

The recently launched startup Cazena, which secured $8 million in funding, aims to streamline big data processes for large enterprises. Leveraging the expertise of its founding team, who previously worked on the data warehouse specialist Netezza (acquired by IBM in 2010), Cazena is well-positioned to deliver on its promise. Prat Moghe, the CEO of Cazena and former senior vice president at Netezza, is supported by Netezza founder Jit Saxena and longtime Netezza CEO Jim Baum, who both serve on Cazena's board. Cazena recognizes that many large companies face challenges in understanding the necessary technologies for deployment. The complexities surrounding Hadoop, NoSQL, Spark, and Elasticsearch often leave them unsure of when and where to utilize these tools. Moreover, transforming these technologies into a functional "data lake," as advocated by some vendors, proves daunting for these companies. Cazena's approach aims to shift the focus from infrastructure to applications, simplifying the big data landscape. To achieve this, Cazena plans to leverage cloud technology.