|
Databricks vs Qubole
May 25, 2023 | Author: Michael Stromann
11
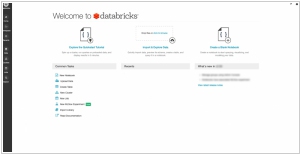
Unified Data Analytics Platform - One cloud platform for massive scale data engineering and collaborative data science.
6
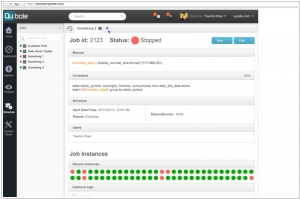
Qubole is a Big Data as a Service (BDaas) Platform Running on Leading Cloud Offerings Like AWS. Qubole enables you to utilize a variety of Cloud Databases and Sources, including S3, MySQL, Postgres, Oracle, RedShift, MongoDB, Vertica, Omniture, Google Analytics, and your on-premise data

See also:
Top 10 Big Data platforms
Top 10 Big Data platforms
Databricks and Qubole are both cloud-based big data platforms that offer managed services for processing and analyzing large-scale data sets. However, there are key differences between the two.
Databricks, founded by the creators of Apache Spark, places a strong emphasis on Apache Spark as the core processing engine. It provides a collaborative and unified environment for data engineers, data scientists, and analysts to work together on data exploration, machine learning, and data engineering tasks. Databricks offers a rich set of features, including automated cluster management, interactive notebooks, and built-in integrations with popular data science libraries.
Qubole, on the other hand, offers a broader range of data processing engines, including Apache Spark, Hadoop, Presto, and more. It aims to provide a multi-engine environment that allows users to choose the best tool for their specific workload. Qubole focuses on providing a scalable and flexible platform with built-in auto-scaling capabilities, intelligent workload management, and deep integration with cloud providers such as AWS, Azure, and GCP.
Additionally, Databricks is often seen as more suited for advanced analytics and machine learning use cases, with extensive support for ML frameworks and libraries, while Qubole caters to a wider range of data processing requirements and provides more flexibility in choosing the right engine for the job.
See also: Top 10 Big Data platforms
Databricks, founded by the creators of Apache Spark, places a strong emphasis on Apache Spark as the core processing engine. It provides a collaborative and unified environment for data engineers, data scientists, and analysts to work together on data exploration, machine learning, and data engineering tasks. Databricks offers a rich set of features, including automated cluster management, interactive notebooks, and built-in integrations with popular data science libraries.
Qubole, on the other hand, offers a broader range of data processing engines, including Apache Spark, Hadoop, Presto, and more. It aims to provide a multi-engine environment that allows users to choose the best tool for their specific workload. Qubole focuses on providing a scalable and flexible platform with built-in auto-scaling capabilities, intelligent workload management, and deep integration with cloud providers such as AWS, Azure, and GCP.
Additionally, Databricks is often seen as more suited for advanced analytics and machine learning use cases, with extensive support for ML frameworks and libraries, while Qubole caters to a wider range of data processing requirements and provides more flexibility in choosing the right engine for the job.
See also: Top 10 Big Data platforms
Databricks vs Qubole in our news:
2014. Big Data as a Service company Qubole raises $13 million

Hadoop-as-a-service startup, Qubole, has secured $13 million in a series B venture capital funding round. Qubole operates on the Amazon Web Services cloud and is also compatible with Google Compute Engine. It functions as a cloud-native Hadoop service, featuring a user-friendly graphical interface, connectors to various data sources (including cloud object stores), and takes advantage of cloud capabilities such as autoscaling and spot pricing for computing resources. Qubole stands out by offering optimized versions of Hive and other MapReduce-based tools, but it also enables data analysis through the use of Facebook's Presto SQL-on-Hadoop engine. Additionally, Qubole is developing a service centered around the Apache Spark framework, which has gained significant popularity due to its speed and efficiency.