|
Apache Drill vs Apache Hive
June 04, 2023 | Author: Michael Stromann
7
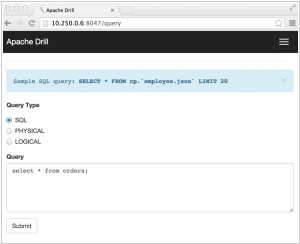
Schema-free SQL Query Engine for Hadoop, NoSQL and Cloud Storage. Get faster insights without the overhead (data loading, schema creation and maintenance, transformations, etc.). Analyze the multi-structured and nested data in non-relational datastores directly without transforming or restricting the data
13
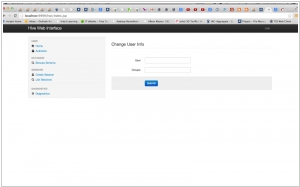
The Apache Hive data warehouse software facilitates querying and managing large datasets residing in distributed storage. Hive provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL. At the same time this language also allows traditional map/reduce programmers to plug in their custom mappers and reducers when it is inconvenient or inefficient to express this logic in HiveQL.

See also:
Top 10 Big Data platforms
Top 10 Big Data platforms
Apache Drill and Apache Hive are both open-source projects that provide SQL-like querying capabilities over big data sets, but they have notable differences in terms of architecture and use cases.
Apache Drill is designed to provide low-latency querying across various data sources, including structured, semi-structured, and unstructured data. It supports schema-free querying, allowing users to explore and query data without the need for predefined schemas or transformations. Drill's distributed execution engine and query optimization capabilities enable it to efficiently query large-scale data sets, making it suitable for interactive data exploration and ad-hoc querying scenarios.
On the other hand, Apache Hive is primarily focused on providing SQL querying and data warehousing capabilities on top of Apache Hadoop. Hive uses a SQL-like language called HiveQL, which translates queries into MapReduce jobs for processing data stored in the Hadoop Distributed File System (HDFS). It is optimized for batch processing and is commonly used for data warehousing and ETL (Extract, Transform, Load) tasks.
One key difference between Drill and Hive is their data source compatibility. Drill supports a wider range of data sources, including HDFS, relational databases, NoSQL databases, cloud storage systems, and more. Hive, on the other hand, primarily works with data stored in HDFS and integrates well with the Hadoop ecosystem.
Another significant difference is their query execution models. Drill uses a distributed execution model that allows for interactive queries and on-the-fly schema discovery. Hive, on the other hand, relies on MapReduce or Tez execution engines, which are more suitable for batch processing and large-scale data analysis.
See also: Top 10 Big Data platforms
Apache Drill is designed to provide low-latency querying across various data sources, including structured, semi-structured, and unstructured data. It supports schema-free querying, allowing users to explore and query data without the need for predefined schemas or transformations. Drill's distributed execution engine and query optimization capabilities enable it to efficiently query large-scale data sets, making it suitable for interactive data exploration and ad-hoc querying scenarios.
On the other hand, Apache Hive is primarily focused on providing SQL querying and data warehousing capabilities on top of Apache Hadoop. Hive uses a SQL-like language called HiveQL, which translates queries into MapReduce jobs for processing data stored in the Hadoop Distributed File System (HDFS). It is optimized for batch processing and is commonly used for data warehousing and ETL (Extract, Transform, Load) tasks.
One key difference between Drill and Hive is their data source compatibility. Drill supports a wider range of data sources, including HDFS, relational databases, NoSQL databases, cloud storage systems, and more. Hive, on the other hand, primarily works with data stored in HDFS and integrates well with the Hadoop ecosystem.
Another significant difference is their query execution models. Drill uses a distributed execution model that allows for interactive queries and on-the-fly schema discovery. Hive, on the other hand, relies on MapReduce or Tez execution engines, which are more suitable for batch processing and large-scale data analysis.
See also: Top 10 Big Data platforms