|
Data Pipeline software
Updated: October 19, 2023
Data pipeline software is a critical tool that automates the movement and processing of data between different systems and applications. These specialized platforms enable organizations to efficiently extract, transform, and load (ETL) data from various sources into a centralized data warehouse or database. Data pipeline software supports data integration from structured and unstructured sources, making it ideal for handling diverse data types. With the ability to schedule data pipelines, these platforms ensure that data is processed and updated in real-time or on a predefined schedule. Data pipeline software also offers data validation and error handling features, ensuring data accuracy and reliability throughout the data flow process. By streamlining data movement and transformation, data pipeline software plays a crucial role in optimizing data analytics, business intelligence, and reporting, empowering organizations to make data-driven decisions with confidence.
See also: Top 10 Business Intelligence software
See also: Top 10 Business Intelligence software
2023. Observability startup Pantomath lands $14M to automate data pipelines
Pantomath, a platform specializing in data observability and traceability, announced a successful $14 million Series A funding round. Pantomath offers organizations a means to detect data quality problems through alerts, troubleshoot using logs and autonomous impact analyses, and pinpoint the root causes of issues for resolution. Although this may seem similar to other data observability platforms in the market, such as Observe (which recently secured $50 million in debt financing), Y Combinator-backed Metaplane, Acceldata, and Manta (which obtained $35 million last year for workforce expansion and tool development), Saxena asserts that Pantomath stands out. According to Saxena, unlike other solutions that primarily focus on data quality by monitoring factors like data volume and freshness within datasets, Pantomath offers a unique approach.
2021. No-code data pipeline platform Hevo raises $30M
Hevo Data, a SaaS startup, has successfully raised $30 million in a recent financing round after experiencing significant growth. Hevo Data specializes in assisting companies in efficiently managing and leveraging their vast amounts of generated and accumulated data. The startup has developed a data pipeline platform that simplifies the integration and retrieval of data from various sources, consolidating them into a single dashboard. Moreover, Hevo Data facilitates the seamless transfer of data to popular cloud data-warehouses such as Snowflake, Google BigQuery, and Amazon Redshift. Manish Jethani, the co-founder and CEO of the startup, elaborated on these capabilities in an interview with TechCrunch.
2021. Orchest raises $3.5M to provide a simpler way to build data pipelines
Orchest, a company dedicated to developing an open-source integrated development environment (IDE) tool specifically for data scientists, has successfully raised $3.5 million in seed funding. The primary goal of Orchest is to empower data scientists by providing them with a self-sufficient platform to develop, iterate, and deploy data pipelines, eliminating the need to depend on infrastructure or engineering teams. By automating various aspects of the workflow, Orchest enables data scientists to seamlessly progress from initial ideation to deployment within a unified environment. This approach liberates data scientists from the burden of resolving complex technological issues and allows them to focus on their core tasks. Orchest strives to enhance the autonomy and efficiency of data scientists by providing an all-in-one solution.
2021. Cribl raises $200M to help enterprises do more with their data
Cribl, a company that is revolutionizing enterprise data management with its "open ecosystem of data," has secured a remarkable $200 million in Series C funding. Cribl's innovative approach involves utilizing unified data pipelines, known as "observability pipelines," to effectively process and direct various types of data flowing through an organization's IT infrastructure. The beauty of Cribl lies in its ability to empower users to select their preferred analytics tools and storage destinations, such as Splunk, Datadog, and Exabeam, without being locked into a single vendor's solution. Moreover, Cribl gives customers the freedom to choose how they store their data, setting it apart from competitors who often restrict companies to their proprietary offerings. By enabling seamless communication between different products, Cribl allows organizations to assemble the best-in-class solutions from various categories, fostering a truly interconnected data ecosystem.
2021. Meroxa raises $15M for its real-time data platform
Meroxa, a startup focused on simplifying the process of building data pipelines to support both analytics and operational workflows, has secured $15 million in a Series A funding round. Meroxa offers a compelling proposition by providing businesses with a unified platform to address their diverse data requirements, eliminating the need for an expert team to construct and manage the underlying infrastructure. Central to Meroxa's solution is a comprehensive software-as-a-service offering that seamlessly connects relational databases to data warehouses, enabling businesses to effectively utilize and operationalize their data. With Meroxa, organizations can streamline their data management processes and unlock valuable insights without the complexities typically associated with data integration and pipeline development.
2021. No-code business intelligence service y42 raises $2.9M
Berlin-based y42, a data warehouse-centric business intelligence service, has recently secured $2.9 million in seed funding. The company, founded in 2020, offers businesses access to an enterprise-level data stack that is as user-friendly as a spreadsheet. With integration capabilities spanning over 100 data sources, including popular B2B SaaS tools like Airtable, Shopify, Zendesk, and database services like Google's BigQuery, y42 enables users to seamlessly incorporate and connect their diverse data sets. Additionally, users can transform and visualize this data, manage data pipelines, and automate workflows based on the insights gained from the integrated data.
2021. Iteratively raises $5.4M to help companies build data pipelines they can trust
As companies accumulate larger volumes of data, ensuring its quality and trustworthiness has become increasingly crucial. After all, an analytics pipeline is only as reliable as the data it gathers, and messy data or bugs can lead to significant issues downstream. Iteratively, a startup dedicated to assisting businesses in constructing dependable data pipelines, has recently secured $5.4 million in seed funding. Iteratively specializes in managing event streaming data for product and marketing analytics, which typically flows into platforms like Mixpanel, Amplitude, or Segment. Positioned at the data source, such as within an app, Iteratively validates and directs the data to the appropriate third-party solutions employed by the company. By doing so, Iteratively helps ensure the accuracy and reliability of the data driving critical business insights.
2020. Avo raises $3M for its analytics governance platform
Avo, a startup dedicated to enhancing data quality management for businesses, has successfully secured a $3 million seed funding round. Avo offers a shared workspace for developers, data scientists, and product managers to collaborate on the development and optimization of data pipelines. Effective product analytics is the result of collective efforts from these cross-functional teams, and Avo aims to provide them with a platform for analytics planning and governance, establishing company-wide standards for creating analytics events.
2020. Data dashboard startup Count raises $2.4M
Count, a startup aiming to create a comprehensive data platform, has successfully secured $2.4 million in funding. Count focuses on providing cost-effective data pipeline building tools to early-stage teams. It offers a centralized solution for aggregating data and generating reports that can be accessed by the entire team. With Count's powerful notebooks, team members can share insights within the relevant context and query data without the need to learn SQL. Count competes with various solutions, including data warehouses like Snowflake, data cleaning tools like DBT, and analytics platforms such as Looker.
2015. Google launched new managed Big Data service Cloud Dataproc
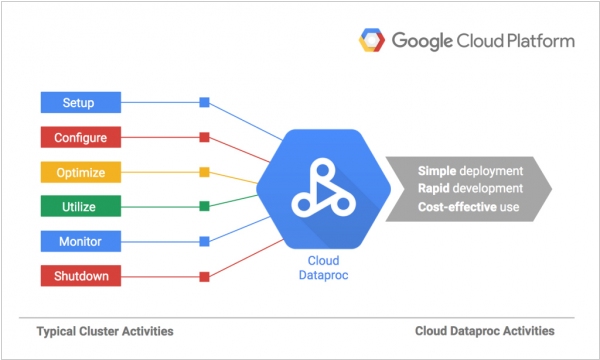
Google is expanding its portfolio of big data services on the Google Cloud Platform with the introduction of Cloud Dataproc. This new service fills the gap between directly managing the Spark data processing engine or Hadoop framework on virtual machines and utilizing a fully managed service like Cloud Dataflow for orchestrating data pipelines on Google's platform. With Cloud Dataproc, users can quickly deploy a Hadoop cluster in less than 90 seconds, which is considerably faster than other available services. Google charges only 1 cent per virtual CPU/hour within the cluster, in addition to the standard costs associated with running virtual machines and storing data. Users can also incorporate Google's more affordable preemptible instances into their clusters to reduce compute costs. Billing is calculated per minute, with a minimum charge of 10 minutes. Thanks to the rapid cluster deployment capabilities of Dataproc, users can easily create ad-hoc clusters when necessary, while Google takes care of the administrative tasks.