|
Google BigQuery vs Hadoop
May 27, 2023 | Author: Michael Stromann
9
BigQuery is a serverless, highly-scalable, and cost-effective cloud data warehouse with an in-memory BI Engine and AI Platform built in.
18
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.

See also:
Top 10 Big Data platforms
Top 10 Big Data platforms
Google BigQuery and Hadoop are both powerful data processing platforms used for handling large datasets and performing analytics. However, they have significant differences in terms of architecture, scalability, and ease of use.
Google BigQuery is a fully managed serverless data warehouse offered by Google Cloud Platform. It is designed for running ad hoc SQL queries on massive datasets. BigQuery excels in providing high-performance analytics with its distributed processing capabilities, columnar storage, and automatic scaling. It abstracts the complexities of managing infrastructure and handles data storage and query execution transparently, making it easy to use for data analysts and scientists.
Hadoop, on the other hand, is an open-source framework that enables distributed processing of large datasets across a cluster of commodity hardware. It consists of the Hadoop Distributed File System (HDFS) for data storage and the MapReduce programming model for distributed data processing. Hadoop offers flexibility and extensibility, allowing users to customize data processing logic and work with a variety of data types. However, it requires more manual configuration and management of the underlying infrastructure.
One key difference between BigQuery and Hadoop is their storage model. BigQuery relies on Google's proprietary storage technology, which enables fast and efficient query execution on structured data. Hadoop, on the other hand, supports both structured and unstructured data and can handle a wider range of data formats.
Another difference lies in scalability and cost. BigQuery automatically scales its resources based on the workload, allowing users to process large datasets without worrying about infrastructure management. In contrast, Hadoop requires manual scaling and cluster management, which can be more complex and time-consuming.
See also: Top 10 Big Data platforms
Google BigQuery is a fully managed serverless data warehouse offered by Google Cloud Platform. It is designed for running ad hoc SQL queries on massive datasets. BigQuery excels in providing high-performance analytics with its distributed processing capabilities, columnar storage, and automatic scaling. It abstracts the complexities of managing infrastructure and handles data storage and query execution transparently, making it easy to use for data analysts and scientists.
Hadoop, on the other hand, is an open-source framework that enables distributed processing of large datasets across a cluster of commodity hardware. It consists of the Hadoop Distributed File System (HDFS) for data storage and the MapReduce programming model for distributed data processing. Hadoop offers flexibility and extensibility, allowing users to customize data processing logic and work with a variety of data types. However, it requires more manual configuration and management of the underlying infrastructure.
One key difference between BigQuery and Hadoop is their storage model. BigQuery relies on Google's proprietary storage technology, which enables fast and efficient query execution on structured data. Hadoop, on the other hand, supports both structured and unstructured data and can handle a wider range of data formats.
Another difference lies in scalability and cost. BigQuery automatically scales its resources based on the workload, allowing users to process large datasets without worrying about infrastructure management. In contrast, Hadoop requires manual scaling and cluster management, which can be more complex and time-consuming.
See also: Top 10 Big Data platforms
Google BigQuery vs Hadoop in our news:
2014. MapR partners with Teradata to reach enterprise customers

The last remaining independent Hadoop provider, MapR, and the prominent big data analytics provider, Teradata, have joined forces to collaborate on integrating their respective products and developing a unified go-to-market strategy. As part of this partnership, Teradata gains the ability to resell MapR software, professional services, and provide customer support. Essentially, Teradata will act as the primary interface for enterprises that utilize or aspire to use both technologies, serving as the representative for MapR. Previously, Teradata had established a close partnership with Hortonworks, but it now extends its collaboration and analytic market leadership to all three major Hadoop providers. Similarly, earlier this week, HP unveiled Vertica for SQL on Hadoop, enabling users to access and analyze data stored in any of the three primary Hadoop distributions—Hortonworks, MapR, and Cloudera.
2014. HP plugs the Vertica analytics platform into Hadoop
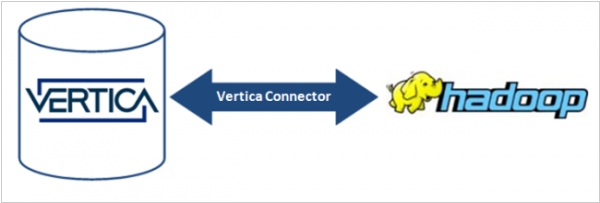
HP has unveiled the introduction of Vertica for SQL on Hadoop, a significant announcement in the world of analytics. With Vertica, customers gain the ability to access and analyze data stored in any of the three primary Hadoop distributions: Hortonworks, MapR, and Cloudera, as well as any combination thereof. Given the uncertainty surrounding the dominance of a particular Hadoop flavor, many large companies opt to utilize all three. HP stands out as one of the pioneering vendors by asserting that "any flavor of Hadoop will do," a sentiment further reinforced by its $50 million investment in Hortonworks, which currently represents the favored Hadoop flavor within HAVEn, HP's analytics stack. HP's announcement not only emphasizes the platform's interoperability but also highlights its capabilities in dealing with data stored in diverse environments such as data lakes or enterprise data hubs. With HP Vertica, organizations gain a seamless solution for exploring and harnessing the value of data stored in the Hadoop Distributed File System (HDFS). The combination of Vertica's power, speed, and scalability with Hadoop's prowess in handling extensive data sets serves as an enticing proposition, potentially motivating hesitant managers to embrace big data initiatives confidently. HP's comprehensive offering provides a compelling avenue for organizations to unlock the potential of their data, urging them to venture beyond their reservations and embrace the world of big data.
2014. Cloudera helps to manage Hadoop on Amazon cloud

Hadoop vendor Cloudera has unveiled a new offering named Director, aimed at simplifying the management of Hadoop clusters on the Amazon Web Services (AWS) cloud. Clarke Patterson, Senior Director of Product Marketing, acknowledged the challenges faced by customers in managing Hadoop clusters while maintaining extensive capabilities. He emphasized that there is no difference between the cloud version and the on-premises version of the software. However, the Director interface has been specifically designed to be self-service, incorporating cloud-specific features like instance-tracking. This enables administrators to monitor the cost associated with each cloud instance, ensuring better cost management.