 |
Cloudera vs MapR
May 25, 2023 | Author: Michael Stromann
12
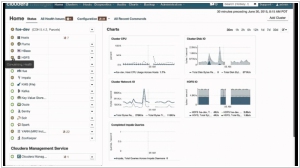
Cloudera helps you become information-driven by leveraging the best of the open source community with the enterprise capabilities you need to succeed with Apache Hadoop in your organization. Designed specifically for mission-critical environments, Cloudera Enterprise includes CDH, the world’s most popular open source Hadoop-based platform, as well as advanced system management and data management tools plus dedicated support and community advocacy from our world-class team of Hadoop developers and experts. Cloudera is your partner on the path to big data.
5
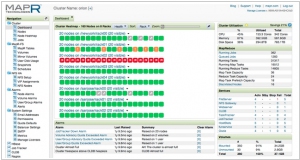
The MapR Distribution for Apache Hadoop provides organizations with an enterprise-grade distributed data platform to reliably store and process big data. MapR packages a broad set of Apache open source ecosystem projects enabling batch, interactive, or real-time applications. The data platform and the projects are all tied together through an advanced management console to monitor and manage the entire system.
Cloudera and MapR were both major players in the Hadoop distribution market, providing enterprise-grade platforms for big data analytics and processing. However, there are notable differences between the two.
Cloudera focused on delivering a comprehensive platform that integrated various components of the Hadoop ecosystem, including Apache Hadoop, Apache Spark, and Apache Hive, into a unified and easy-to-use solution. They offered additional management and security features, making it suitable for organizations looking for a complete end-to-end solution.
MapR, on the other hand, differentiated itself by offering a unique file system architecture, known as the MapR File System (MapR-FS). MapR-FS provided significant performance and scalability advantages over traditional Hadoop Distributed File System (HDFS) implementations. In addition, MapR offered its own set of tools and frameworks for real-time data processing, such as MapR Streams and MapR-DB, which contributed to its positioning as a platform for mission-critical, real-time data applications.
In terms of business models, Cloudera primarily focused on selling subscriptions and support services, while MapR initially relied heavily on software licenses. However, in 2019, MapR faced financial challenges and was acquired by Hewlett Packard Enterprise (HPE), which subsequently integrated MapR technologies into their product portfolio.
It's worth noting that the Hadoop landscape has undergone significant changes since then, with many organizations shifting towards cloud-based analytics and data processing platforms. Both Cloudera and MapR have evolved their offerings to adapt to these changes and provide cloud-native solutions.
See also: Top 10 Public Cloud Platforms
Cloudera focused on delivering a comprehensive platform that integrated various components of the Hadoop ecosystem, including Apache Hadoop, Apache Spark, and Apache Hive, into a unified and easy-to-use solution. They offered additional management and security features, making it suitable for organizations looking for a complete end-to-end solution.
MapR, on the other hand, differentiated itself by offering a unique file system architecture, known as the MapR File System (MapR-FS). MapR-FS provided significant performance and scalability advantages over traditional Hadoop Distributed File System (HDFS) implementations. In addition, MapR offered its own set of tools and frameworks for real-time data processing, such as MapR Streams and MapR-DB, which contributed to its positioning as a platform for mission-critical, real-time data applications.
In terms of business models, Cloudera primarily focused on selling subscriptions and support services, while MapR initially relied heavily on software licenses. However, in 2019, MapR faced financial challenges and was acquired by Hewlett Packard Enterprise (HPE), which subsequently integrated MapR technologies into their product portfolio.
It's worth noting that the Hadoop landscape has undergone significant changes since then, with many organizations shifting towards cloud-based analytics and data processing platforms. Both Cloudera and MapR have evolved their offerings to adapt to these changes and provide cloud-native solutions.
See also: Top 10 Public Cloud Platforms
Cloudera vs MapR in our news:
2022. Cloudera launches its all-in-one SaaS data lakehouse
Cloudera, the company that specializes in big data with a focus on Hadoop, is now shifting its focus towards becoming the unified data fabric for hybrid data platforms. Taking a step further in this direction, the company recently launched its Cloudera Data Platform (CDP) One, a data lakehouse as a service (LaaS). This managed offering aims to provide enterprises with a platform that enables self-service analytics and data access for a broader range of employees. While Databricks, known for popularizing the lakehouse concept, also offers SaaS-based solutions, Cloudera positions its service as the "first all-in-one data lakehouse SaaS offering." Cloudera emphasizes that its service combines compute, storage, machine learning, streaming analytics, and enterprise security, making it a comprehensive solution for organizations.
2019. HPE acquires big data platform MapR

Hewlett Packard Enterprises (HPE) has completed the acquisition of MapR Technologies, a leading distributor of a data analytics platform based on Hadoop. This strategic deal encompasses the transfer of MapR's technology, intellectual property, and expertise in domains such as AI, machine learning, and analytics data management. By incorporating MapR's portfolio, HPE aims to reinforce its existing offerings in the field of big data, complementing the BlueData software acquisition it made in November. BlueData's software facilitates a container-based approach for deploying and managing Hadoop, Spark, and other environments across bare metal, cloud, or hybrid platforms. The inclusion of the MapR platform brings additional capabilities for running distributed applications, including storage APIs such as S3 API, along with APIs for HDFS, POSIX, NFS, and Kafka.
2018. Big Data platforms Cloudera and Hortonworks merge

Over time, Hadoop, the once-prominent open-source platform, fostered the growth of numerous companies and an ecosystem of vendors. However, the complexity associated with Hadoop posed a significant challenge. This is where companies like Hortonworks and Cloudera stepped in, offering packaged solutions for IT departments seeking the advantages of a big data processing platform without the need to build Hadoop from scratch. These companies provided various approaches to tackle the complexity, but as cloud-based big data solutions gained prominence, the notion of implementing a Hadoop system from scratch became less compelling, even with the assistance of firms like Cloudera and Hortonworks. Today, both companies have announced their merger in a deal valued at $5.2 billion. The combined entity will serve a customer base of 2,500, generate $720 million in revenue, and possess $500 million in cash reserves, all while remaining debt-free.
2015. MapR tries to separate from Hadoop
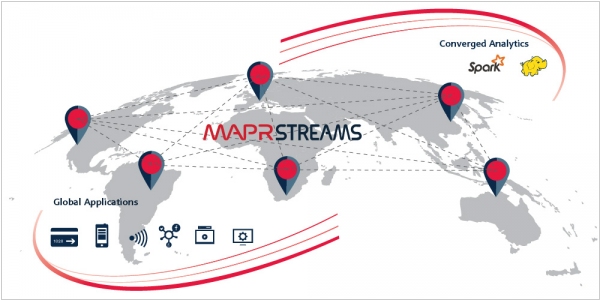
MapR is among the companies operating on the open-source Hadoop platform, facing competition in this domain. To establish a distinctive position among its well-established competitors, MapR has unveiled a new product called MapR Streams. This innovative offering enables the continuous processing of data, allowing for the creation of custom offers by feeding consumer data to advertisers or the distribution of health data to medical professionals to personalize medication and treatment options. These capabilities operate in near real-time, empowering customers to share data sources with individuals or machines that require access to such information through a subscription-based model. For instance, a maintenance program could subscribe to data streams from a manufacturer's shop floor, acquiring insights on usage, production, bottlenecks, and wear and tear. Alternatively, IT departments could subscribe to data streams containing log information, enabling them to detect anomalies that indicate maintenance issues or security breaches.
2015. Hortonworks acquired dataflow solutions developer Onyara
Hortonworks, a publicly traded company that offers a commercial distribution of the open-source big data software Hadoop, has announced its acquisition of Onyara, an early-stage startup known for the development of Apache NiFi. This open-source software originated within the National Security Agency (NSA) and enables efficient delivery of sensor data to appropriate systems while maintaining data tracking capabilities. In addition to previous acquisitions like XA Secure and SequenceIQ, Hortonworks has now expanded its portfolio with the intention of introducing a new subscription service based on Apache NiFi. This subscription will be marketed under the name Hortonworks DataFlow.
2015. MapR adds Apache Drill to its Hadoop distribution

MapR has recently announced that its Hadoop distribution now includes Apache Drill, an open-source SQL query engine designed for Hadoop and NoSQL environments. Apache Drill offers low-latency capabilities, making it easier for end users to interact with diverse data sources, including legacy transactional systems, Internet of Things (IoT) sensors, web click-streams, and semi-structured data. Furthermore, it provides compatibility with popular business intelligence (BI) and data visualization tools. The inclusion of Apache Drill 1.0 in MapR's distribution grants users free access to this powerful tool. As a result, competitors like Hortonworks, who have contributors involved in the Apache Drill project, can also consider incorporating it into their own distribution if they find it valuable.
2015. MapR revamps its Hadoop platform with more real-time analytics

The most recent version of the enterprise-grade distributed Hadoop data platform MapR is specifically designed for the modern data-centric enterprise, emphasizing real-time capabilities. Its advanced features include table replication, which enables the simultaneous updating of multiple instances in different locations while ensuring synchronized changes across them. The ability to respond promptly to real-time business needs and offer the right solutions is crucial. Failure to do so not only means missed opportunities but can also pose a threat to a company's sustainability. This is one of the reasons why some enterprises are opting for MapR instead of traditional relational database management systems (RDBMS). MapR provides a comprehensive solution that combines a highly regarded NoSQL database and Hadoop in a convenient package. Unlike competitors such as Hortonworks and Cloudera, MapR stands out as a software company focused on simplifying the implementation of big data solutions, making it more accessible and user-friendly.
2015. Google partners with Cloudera to bring Cloud Dataflow to Apache Spark
Google has announced a collaboration with Cloudera, the Hadoop specialists, to integrate its Cloud Dataflow programming model into Apache's Spark data processing engine. By bringing Cloud Dataflow to Spark, developers gain the ability to create and monitor data processing pipelines without the need to manage the underlying data processing cluster. This service originated from Google's internal tools for processing large datasets at a massive scale on the internet. However, not all data processing tasks are identical, and sometimes it becomes necessary to run tasks in different environments such as the cloud, on-premises, or on various processing engines. With Cloud Dataflow, data analysts can utilize the same system to create pipelines, regardless of the underlying architecture they choose to deploy them on.
2014. MapR partners with Teradata to reach enterprise customers

The last remaining independent Hadoop provider, MapR, and the prominent big data analytics provider, Teradata, have joined forces to collaborate on integrating their respective products and developing a unified go-to-market strategy. As part of this partnership, Teradata gains the ability to resell MapR software, professional services, and provide customer support. Essentially, Teradata will act as the primary interface for enterprises that utilize or aspire to use both technologies, serving as the representative for MapR. Previously, Teradata had established a close partnership with Hortonworks, but it now extends its collaboration and analytic market leadership to all three major Hadoop providers. Similarly, earlier this week, HP unveiled Vertica for SQL on Hadoop, enabling users to access and analyze data stored in any of the three primary Hadoop distributions—Hortonworks, MapR, and Cloudera.
2014. Enterprise Hadoop provider Hortonworks filed for an IPO

Hortonworks, the company developing commercial Hadoop technology, has submitted its initial public offering (IPO) filing. With over $33 million in revenue and an operating loss of nearly $88 million, the company has showcased its financial performance for the current year. Hortonworks emerged as a separate entity from Yahoo in 2011 and provides a comprehensive big data processing platform. This platform enables the processing of diverse data types, including SQL and NoSQL sources, and facilitates data search and visualization using various analytics tools. Hortonworks is renowned for its exclusive focus on Hadoop, offering a solution devoid of any proprietary extensions.

