|
Apache Hive vs Apache Spark
June 03, 2023 | Author: Michael Stromann
13
The Apache Hive data warehouse software facilitates querying and managing large datasets residing in distributed storage. Hive provides a mechanism to project structure onto this data and query the data using a SQL-like language called HiveQL. At the same time this language also allows traditional map/reduce programmers to plug in their custom mappers and reducers when it is inconvenient or inefficient to express this logic in HiveQL.
17
Apache Spark is a fast and general engine for large-scale data processing. Run programs up to 100x faster than Hadoop MapReduce in memory, or 10x faster on disk. Write applications quickly in Java, Scala or Python. Combine SQL, streaming, and complex analytics.
Apache Hive and Apache Spark are both powerful big data processing frameworks, but they have different approaches and use cases.
Apache Hive is a data warehouse infrastructure built on top of Apache Hadoop. It provides a SQL-like interface for querying and analyzing structured data stored in distributed file systems. Hive is particularly useful for large-scale batch processing and data analytics, as it offers a high-level query language (HiveQL) that translates SQL-like queries into MapReduce jobs, allowing users to leverage the scalability and fault tolerance of Hadoop.
Apache Spark, on the other hand, is a fast and general-purpose data processing engine that supports batch processing, real-time streaming, machine learning, and graph processing. Spark provides an in-memory computing model that enables faster data processing compared to traditional disk-based systems like Hive. It also offers a rich set of APIs in various programming languages, such as Scala, Java, and Python, making it more versatile and suitable for a wide range of data processing tasks.
See also: Top 10 Big Data platforms
Apache Hive is a data warehouse infrastructure built on top of Apache Hadoop. It provides a SQL-like interface for querying and analyzing structured data stored in distributed file systems. Hive is particularly useful for large-scale batch processing and data analytics, as it offers a high-level query language (HiveQL) that translates SQL-like queries into MapReduce jobs, allowing users to leverage the scalability and fault tolerance of Hadoop.
Apache Spark, on the other hand, is a fast and general-purpose data processing engine that supports batch processing, real-time streaming, machine learning, and graph processing. Spark provides an in-memory computing model that enables faster data processing compared to traditional disk-based systems like Hive. It also offers a rich set of APIs in various programming languages, such as Scala, Java, and Python, making it more versatile and suitable for a wide range of data processing tasks.
See also: Top 10 Big Data platforms
Apache Hive vs Apache Spark in our news:
2015. IBM bets on big data Apache Spark project

IBM has made a significant announcement regarding its involvement in the open source big data project Apache Spark. The company plans to allocate a team of 3,500 researchers to this initiative. Additionally, IBM has unveiled its decision to open source its own IBM SystemML machine learning technology. These strategic moves are aimed at positioning IBM as a frontrunner in the domains of big data and machine learning. Cloud, big data, analytics, and security form the pillars of IBM's transformation strategy. In conjunction with this announcement, IBM has committed to integrating Spark into its core analytics products and partnering with Databricks, the commercial entity established to support the open source Spark project. IBM's participation in these endeavors goes beyond mere altruism. By actively engaging with the open source community, IBM aims to establish itself as a trusted contributor in the realm of big data. This, in turn, enhances its credibility among companies working on big data and machine learning projects using open source tools. The collaborative involvement with the community opens doors for IBM to offer consulting services and seize other business opportunities in this space.
2015. Google partners with Cloudera to bring Cloud Dataflow to Apache Spark
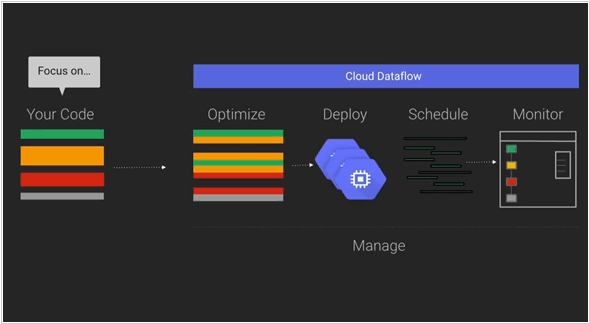
Google has announced a collaboration with Cloudera, the Hadoop specialists, to integrate its Cloud Dataflow programming model into Apache's Spark data processing engine. By bringing Cloud Dataflow to Spark, developers gain the ability to create and monitor data processing pipelines without the need to manage the underlying data processing cluster. This service originated from Google's internal tools for processing large datasets at a massive scale on the internet. However, not all data processing tasks are identical, and sometimes it becomes necessary to run tasks in different environments such as the cloud, on-premises, or on various processing engines. With Cloud Dataflow, data analysts can utilize the same system to create pipelines, regardless of the underlying architecture they choose to deploy them on.