|
Amazon EMR vs Google Cloud Dataflow
June 04, 2023 | Author: Michael Stromann
11
Amazon EMR is a service that uses Apache Spark and Hadoop, open-source frameworks, to quickly & cost-effectively process and analyze vast amounts of data.
4
Build, deploy, and run data processing pipelines that scale to solve your key business challenges. Google Cloud Dataflow enables reliable execution for large scale data processing scenarios such as ETL, analytics, real-time computation, and process orchestration.
Amazon EMR (Elastic MapReduce) and Google Cloud Dataflow are both powerful big data processing platforms, but they differ in their architecture, programming models, and integration with cloud ecosystems. Amazon EMR is a managed cluster platform that enables the processing of large-scale data using popular big data frameworks like Apache Spark, Hadoop, and Presto. It allows users to easily provision, scale, and manage clusters for data processing and analysis. Amazon EMR integrates seamlessly with other AWS services, making it a preferred choice for users already leveraging the AWS ecosystem. On the other hand, Google Cloud Dataflow is a fully managed data processing service that provides a unified programming model for both batch and stream processing. It allows developers to write data pipelines in popular programming languages like Java and Python using the Apache Beam framework. Google Cloud Dataflow offers automatic scaling, built-in fault tolerance, and easy integration with other Google Cloud services, making it suitable for users who prefer a streamlined and serverless data processing solution..
See also: Top 10 Big Data platforms
See also: Top 10 Big Data platforms
Amazon EMR vs Google Cloud Dataflow in our news:
2015. Google partners with Cloudera to bring Cloud Dataflow to Apache Spark
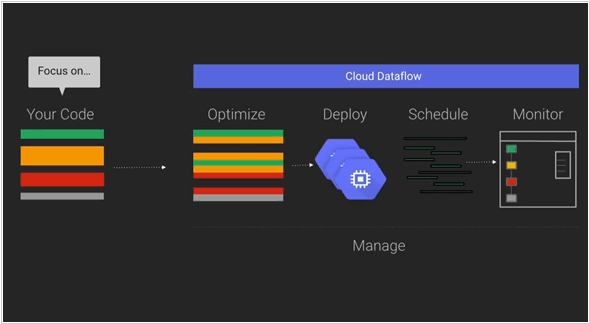
Google has announced a collaboration with Cloudera, the Hadoop specialists, to integrate its Cloud Dataflow programming model into Apache's Spark data processing engine. By bringing Cloud Dataflow to Spark, developers gain the ability to create and monitor data processing pipelines without the need to manage the underlying data processing cluster. This service originated from Google's internal tools for processing large datasets at a massive scale on the internet. However, not all data processing tasks are identical, and sometimes it becomes necessary to run tasks in different environments such as the cloud, on-premises, or on various processing engines. With Cloud Dataflow, data analysts can utilize the same system to create pipelines, regardless of the underlying architecture they choose to deploy them on.